
Table des matières
Imaginez un élève qui, sans professeur, apprend à résoudre des équations complexes en s’auto-évaluant grâce à des récompenses. Maintenant transposons cela à l’IA : c’est exactement ce que Recherche profondeune startup chinoise, avec son modèle DeepSeek-R1. Ce dernier rivalise avec OpenAI o1 (Modèle phare d’Openai pour la résolution de problèmes) en mathématiques, code et raisonnement… à un coût 95% inférieur ! Et cerise sur le gâteau : le modèle est open-source. Immergé dans une innovation qui pourrait redéfinir l’accès à l’IA avancée. ðÿ˜š
Pour comprendre cette avancée, il faut se plonger dans deux concepts clés : le Apprentissage par renforcement (RL) et le Réglage fin supervisé (SFT).
Le Apprentissage par renforcement (RL) Fonctionne comme un enfant qui apprend à jouer aux échecs. Il tente des coups, gagne parfois, perd souvent et ajuste sa stratégie en fonction des récompenses (victoires) ou des punitions (défaites). Le RL fonctionne de la même manière : le modèle DeepSeek-R1-Zéro (version initiale) appris Sans données étiquetéesuniquement en testant des solutions, en recevant des « récompenses » virtuelles pour ses bonnes réponses et en affinant son raisonnement.
Après cette phase autodidacte, Deepseek a ajouté un « tuteur humain » via le Réglage fin supervisé (SFT). Le modèle a été affiné avec des données supervisées pour corriger ses erreurs (par exemple réponses confuses ou mélange de langues) et améliorer sa clarté.
Pensez à un athlète qui s’entraîne seul (RL), puis peaufine sa technique avec un coach (SFT).
Recherche profonde utilisée DeepSeek-V3un modèle open source existant, comme point de départ. Ensuite, le modèle a été élaboré pour des millions de problèmes mathématiques, de code et de logique, sans correction humaine. Il a appris à auto-évaluation ses réponses via un système de récompense. Pour corriger les défauts (par exemple le manque de lisibilité), les chercheurs ont ajouté des exemples de réponses idéales, comme par exemple un enseignant qui montre la bonne méthode. Enfin, une combinaison de RL et SFT a permis d’équilibrer créativité et précision. Tout cela l’a rendu capable de résoudre des problèmes complexes de mathématiques, de codage et de raisonnement, en concurrence avec OpenAI o1l’un des leaders dans le domaine.
🫠Š Performances – un modèle qui rivalise avec les humains (et les géants de l’IA)
Deepseek-R1 a été testé sur plusieurs benchmarks, démontrant des performances impressionnantes.
Dans mathématiquesil a obtenu 79,8% de réussite à l’AIM 2024, une épreuve ultra-complexe réservée aux meilleurs lycéens américains, contre 79,2% pour l’Openai O1. Sur l’ensemble de données Math-500, qui comprend des problèmes de niveau universitaire, la précision a atteint 97,3 %.
Dans programmationDeepseek-R1 a obtenu un score de 2 029 sur le code CodeForces, dépassant 96,3 % des participants humains. Le modèle résout des défis algorithmiques en un temps limité, comme l’optimisation du tri des données ou la gestion de structures complexes. Il peut par exemple générer un code pour trouver le chemin le plus court dans un labyrinthe 3D, tout en expliquant sa logique.
Dans Culture générale et logiqueDeepseek-R1 a atteint une précision de 90,8% au MMLU (Massive Multitask Language Understanding), contre 91,8% pour Openai O1. Ce test couvre divers domaines tels que la philosophie, l’histoire et les sciences. Par exemple, si vous demandez “Expliquez la théorie de la relativité d’Einstein à un enfant de 10 ans”le modèle décompose les concepts de métaphores simples (ex : “imaginez que l’espace est une couverture étendue…”).
💡 Pourquoi Deepseek R1 change la donne ?
La recherche profonde est source ouvertece qui signifie que chacun peut accéder à son code, l’utiliser, voire l’améliorer. C’est comme si une entreprise ouvrait les plans d’une voiture électrique révolutionnaire et disait : « Prenez ce que vous voulez et faites-le encore mieux ! ». Par conséquent l’industrie de l’IA a vu émerger plusieurs modèles dérivés (ex : Qwen-1.5B) GPT-4O surpasse. La communauté peut adapter Deepseek à des niches : éducation, santé, finance…
Et ce n’est pas tout : l’un des aspects les plus révolutionnaires de Deepseek-R1 est son coût divisé par 20 par rapport à Openai O1. Par exemple :
- OpenAI o1 facture 15 $ par million de jetons analysés comme démarreur.
- Deepseek-R1 ne coûte que 0,55 $ Pour le même service.
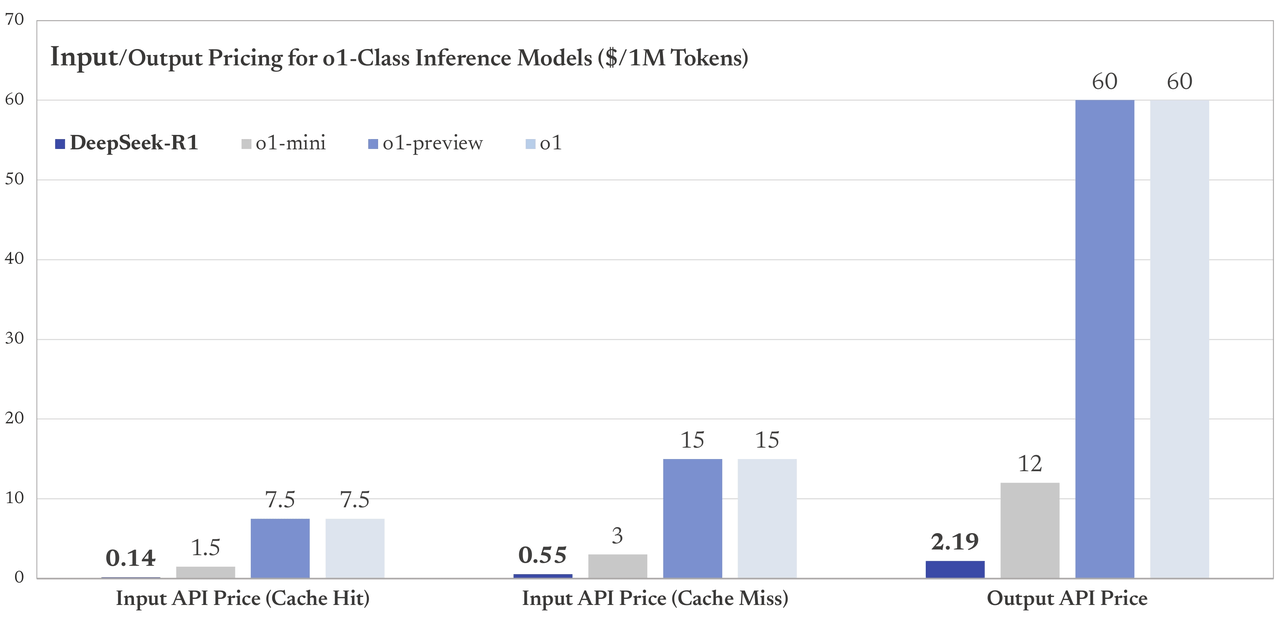
Imaginez les possibilités pour les petites entreprises, les développeurs indépendants ou même les étudiants qui souhaitent expérimenter une IA puissante sans dépenser une fortune.
ðÿ ”® L’avenir de l’IA open source
Deepseek-R1 n’est pas seulement un modèle d’IA, c’est un signal clair que l’open source peut rivaliser avec les titans commerciaux dans la course vers leIntelligence artificielle générale (AG) – une IA capable d’accomplir des tâches intellectuelles comme un humain. Cette avancée soulève une question cruciale : Et si AG (Général) n’était plus réservé aux géants technologiques ?
Dans un premier scénario, les startups open source pourraient dépasser les géants en agilité. Par exemple, IA de stabilité (Creator of Stable Diffusion) a montré que l’open source peut dominer un secteur (génération d’images).
Les implications sont gigantesques :
- Accessibilité : Des outils ultra puissants deviennent accessibles à tous.
- Innovation accélérée : La transparence encourage la collaboration et les progrès rapides.
- Démocratisation de l’IA : Pas besoin d’un budget astronomique pour expérimenter ou développer une IA avancée.
Cependant, cette démocratisation soulève Risques éthiques non publiés. Si quelqu’un peut conduire à une IA surpuissante, comment éviter les abus (Deepfakes, Désinformation) ?
Le rôle des gouvernements et de la communauté sera crucial. Faut-il réglementer l’accès aux modèles open source ? Ou au contraire financer des projets éthiques (ex : l’IA pour le climat) ?
ðÿš Étres deepseek R1 – pas encore parfait
Malgré ses performances impressionnantes, R1 présente certaines limites.
Le modèle initial (R1-Zéro) mélangeait parfois les langages ou produisait des explications confuses. Bien que la phase SFT ait corrigé ces défauts, des erreurs subsistent dans les réponses longues.
De plus, les benchmarks comme MMLU ou Codefoces sont majoritairement en anglais. Le modèle pourrait être moins performant sur des problèmes culturellement spécifiques (par exemple, dialectes locaux, contextes non occidentaux).
Deepseek ouvre des possibilités infinies aux développeurs, chercheurs et entrepreneurs.
Dans éducationvous pourriez créer un tuteur IA pour les élèves en difficulté. Dans DevOpsle modèle peut générer des scripts automatisés pour le déploiement AWS ou la résolution de bogues. Dans rechercheil permet de simuler des problèmes complexes, comme la modélisation climatique.
𠑉 pour les tests deepsekr1, le Le modèle est disponible dans le chatbot ici : Chat Deepseek.
💉 Pour intégrer Deepseekr1 à votre projet, deux options s’offrent à vous : utiliser l’API Deepseek ( – aussi simple que Chatgpt – ou télécharger le modèle sur Hugging Face (pour un contrôle total.
ðÿœÿ L’Open-Source peut-il gagner la guerre de l’IA ?
Deepseekr1 n’est pas seulement un modèle, c’est un symbole. Il prouve que l’innovation peut non seulement venir de la Silicon Valley, mais aussi de collaborations mondiales et open source. Cette avancée rappelle une citation inspirante d’Alan Kay : “La meilleure façon de prédire l’avenir est de le créer.”
🙋 Et vous, qu’en pensez-vous ? :
-
Faut-il limiter l’accès à une IA puissante pour éviter les abus, même si cela ralentit l’innovation ?
-
Comment se préparer à un monde où l’IA open source concurrence les outils propriétaires ?
-
Comment notre continent peut-il profiter de ces technologies sans dépendre des États-Unis ou de la Chine ?
💉 Passez à l’action : Testez Deepseek-R1, partagez vos projets en commentaires et discutez ensemble de ce futur passionnant !