
Table des matières
Dans l’imagination collective, le terme “” Impiation € ¯ “n’a aucune relation avec” Meta “mais fait plutôt référence à ces téléchargeurs clandestins de blockbusters hollywoodiens ou de jeux vidéo ultra-populaires. Mais saviez-vous qu’il y a aussi des pirates… des livres € ¯? Oui, ces «€ ¯flibusiers littéraires € ¯» qui marchent sur le Web pour trouver des romans, des manuels, des encyclopédies et d’autres trésors de la connaissance. Des plates-formes telles que Z-Library ou Library Genesis (Libgen) sont pleines d’œuvres à portée cliquepour le meilleur et pour le pire.
Jusque-là, nous aurions pensé que seuls quelques étudiants tondus ou des amateurs de lecture quelque peu rebelles s’aventuraient sur ces sites. Et puis un jour, grande surprise: Méta (Ex-Facebook) serait lui-même devenu l’un des plus grands “Âpirés de livres € ¯” sur la planète. Oui, vous avez bien lu. D’après la compagnie de Mark Zuckerberg, nous attendons peut-être un nouveau réseau social ou un casque de réalité virtuelle, pas qu’il recherche des millions de livres illégalement. Alors accrochez vos ceintures, armez-vous de votre meilleure couverture oculaire et plongez ensemble dans cette histoire incroyable.
Une brève histoire de la piratage littéraire
Avant de jeter un œil aux pratiques de Meta, revenons au piratage des livres en général. Nous pensons souvent à P2P (peer-to-peer) pour télécharger des films, des séries ou de la musique. Cependant, les communautés se sont également formées pour partager des PDF de romans, d’articles scientifiques et de manuels. L’idée de initialement ¯? Rendre les connaissances accessibles à tous, en particulier lorsque certains travaux académiques sont vendus à des prix exorbitants.
Des sites comme Libgen ou Z-Library répertorient ainsi des centaines de milliers, voire des millions, des titres, allant de l’obscur essai philosophique au roman à succès. Tout cela est évidemment illégal en ce qui concerne le droit d’auteur, mais ces plateformes restent une aubaine pour les étudiants inhabituels et la curieuse insatiable. En gros : Même si c’est interdit, c’est drôle d’essayer de pouvoir télécharger n’importe quel livre en quelques secondes.
Le mécanisme est similaire à celui d’autres formes de piratage en ligne: BitTorrent. Nous nous connectons à un “” Torrent “” qui contient le livre que nous voulons, et nous téléchargeons le fichier en partageant les extrémités de ce dernier avec d’autres utilisateurs. Pour que ce système se tourne correctement, vous devez rester en mode graine (Envoyez les chansons déjà téléchargées) une certaine heure, afin de maintenir un “” ” essaim) solide.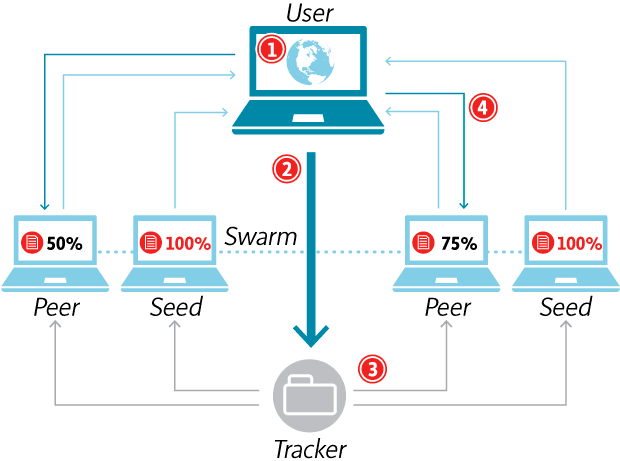
Bien sûr, en ce qui concerne les films et les séries, les éditeurs et leurs avocats surveillent le grain. Certains d’entre eux connectent Incognito aux torrents et collectent les adresses IP des téléchargeurs. Ils peuvent ensuite contacter les fournisseurs d’accès Internet (ISP) pour identifier les «« imptères € ¯pir € ¯ »et leur envoyer des lettres menaçantes, juste pour leur donner envie de partager le dernier best-seller. Vous avez peut-être déjà entendu parler de ces célèbres lettres de préavis formelles …
Récemment, la nouvelle est tombée comme un pavage dans l’étang (ou un livre dans la bibliothèque, comme souhaité): Méta aurait téléchargé plus de 81.7 Téraoctets livres, juste au printemps dernier, sur différents bibliothèques de l’ombre (Z-Library, Libgen, Archive d’Anna, etc.). Et ce n’est pas tout: avant cela, l’entreprise aurait déjà pompé 80 Téraoctets Articles scientifiques. En toutNous sommes à peu près Les 160 Teraoctets de contenu piraté – suffisamment pour remplir un nombre colossal de lecteurs et de bibliothèques virtuelles.
Pour donner une idée, 80 Teraoctes de textes sont plus d’un milliard scanné. Imaginez un instant la pile de livres correspondante dans votre salon … clairement, Meta n’était pas satisfaite de “” Voller une livraison € ¯ “: elle a carrément embarqué tout le département littéraire du supermarché, le carton de la librairie en face, Et peut-être même la réserve de la bibliothèque municipale € ¯!
La réponse est plus simple qu’il n’y paraît: l’as. Les intelligences artificielles actuelles, telles que les modèles de langue (Chatgpt, Llama, etc.), ont besoin de quantités stupéfiantes de texte pour s’entraîner pour comprendre et générer un langage. Plus ils sont donnés de livres, plus ils deviennent efficaces.
Cependant, pour obtenir légalement des millions de livres, en particulier les manuels et les articles scientifiques, est un parcours obstacle. Les prix sont élevés, le complexe de licences et même une entreprise comme Meta peut hésiter à investir des centaines de millions de dollars juste pour enrichir sa base de données. Le plus pratique (et le plus juridiquement douteux): Tournez-vous vers les torrents. Ni vu ni connu … du moins, en théorie.
Selon des documents judiciaires, Meta aurait pris soin de N’utilisez pas les adresses IP officielles Pour télécharger ces livres, juste pour ne pas susciter. Imaginez la scène: un pirate aléatoire dans le essaim tombe sur une adresse IP qui se réfère directement à “” “Effet garanti! Il aurait immédiatement tweeté quelque chose comme: “” Smokes, Facebook vient de télécharger tout le département romantique de la bibliothèque des pirates! “” “
En interne, les employés se sont plaints: “” torrent D’un travail de travail… «». Malgré cet inconfort, la pratique s’est poursuivie. La cerise sur le gâteau: le grand patron, Mark Zuckerberg, a juré qu’il n’était pas au courant, mais les discussions internes le contredisent. En d’autres termes, il était probablement dans la boucle lorsque Meta a dit qu’il était: “” Illégalement, “eh bien, pourquoi pas …” “.
Les conséquences (morale, légale et tout le bazar)
On pourrait dire: “” “Ce n’est que des livres. Est-ce vraiment si sérieusement ¯?” “. En réalité, oui. Premièrement, cette pratique est un coup dur pour la propriété intellectuelle. Les auteurs, en particulier les moins connus, dépendent de leur droit d’auteur pour vivre. Lorsque vous piratez un livre, vous les privez potentiellement de revenus. Quand c’est Méta Qui faufile des milliers de livres, l’impact est encore plus colossal.
Ensuite, il y a la question de l’utilisation faite de ces textes. Meta ne l’utilise pas pour distraire ses employés entre deux pauses café, mais pour former et, en fin, faire de l’argent. Nous pouvons comprendre la frustration des éditeurs: “” Nous vendons ces livres, et les méta les récupèrent gratuitement pour développer une IA qui pourrait un jour remplacer de nombreuses professions de création. C’est un peu fort, pas ¯? “” ” .
Enfin, il y a une dimension presque philosophique: Qu’est-ce qu’une œuvre, si elle est aspirée par des algorithmes et remixé sans cesse € ¯? Les écrivains craignent de voir leur style et leurs idées réutilisées par l’IA capable de publier des romans dans un claquement de doigts. Nous pouvons nous retrouver face à un tsunami de contenu généré, noyant la production humaine, sans rémunération réelle pour les créateurs originaux.
Vers une armada de livres écrits par l’IA?
Depuis des années, nous assistons à une vague de fanfictions, d’articles et de textes générés ou co-gérés par des modèles de langue. L’idée que l’IA peut jeter un roman à succès n’est plus excentrique. En outre, les géants du divertissement (et du merchandising) ont bien compris cela: pourquoi payer des écrivains ou des auteurs lorsque vous pouvez générer des univers dans les univers “” “Cle en main” pour vendre des jouets, des films, des parcs à thème € ¯?
Les auteurs des best-sellers craignent de perdre la main sur leur propre création. Et quand vous savez que, pour certains écrivains, les revenus ne viennent même plus de autant de livres, mais des adaptations de cinéma ou des produits dérivés … c’est un marché tentaculaire qui est menacé. Après tout, on pourrait imaginer que l’IA conçoit tout un univers transmédia, du roman à la série télévisée, y compris la gamme de figurines, sans aucun humain n’ayant mis le stylo sur le papier.
La question reste complexe. D’une part, on ne peut ignorer que de nombreux lecteurs se tournent vers ces bibliothèques de pirates car ils ne peuvent pas se permettre d’acheter tous les livres qu’ils souhaitent, ou parce qu’ils doivent accéder aux travaux de recherche bloqués derrière murs de paiement. D’un autre côté, le piratage a des auteurs et des éditeurs préjudiciables, et l’échelle Le piratage de Meta soulève de sérieuses questions sur les méthodes des géants de la technologie.
Devrions-nous renforcer les lois € ¯? Imposer de nouveaux modèles de financement pour la culture et la recherche € ¯? Configurer des bibliothèques numériques légales, financées par un système partagé € ¯? Ou acceptez que les connaissances circulent, même d’une manière illégale, car les connaissances doivent être accessibles € ¯?
La grande question: les pirates ou les sauveurs de Know -How € ¯?
Pour beaucoup, le piratage littéraire reste un geste militant, un nez de l’industrie de l’édition traditionnelle, trop gourmand. Pour d’autres, c’est un fléau qui prive les auteurs d’une rémunération équitable et, à long terme, décourage la création. Au milieu de tout çaMeta a créé un vrai électrochoc: voir un Titan numérique saisissant notre “€ ¯Héritage littéraire € ¯” pour le servir dans le pâturage à son IA, ce qui vous fait réfléchir.
L’avenir est incertain. Les éditeurs continueront de se battre, les Pirates pour s’organiser et les grandes entreprises technologiques pour contourner la loi avec de grands serveurs et des adresses IP masquées. Qui sortira victorieux de cette bataille. Difficile à dire. Une chose est certaine: la révolution numérique n’a pas fini de secouer le monde du livre.
Et vous, que pensez-vous?
Devrions-nous repenser complètement la façon dont les auteurs sont payés et protéger les œuvres à l’ère de l’IA, ou est-il inévitable que le partage (légal ou non) règne en maître dans le nom de l’accès universel aux connaissances?